目录
提出问题:
- 受欢迎程度及评分的分布
- 哪些公司的作品平均评分更高,更受欢迎?
- 票房高的电影有哪些特点?
In [1]:
# 导入语句。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(color_codes=True)
# 务必包含一个‘magic word’(带有“%”的***),以便将视图
# 与 notebook 保持一致。关于更多信息,请访问该网页:
# http://ipython.readthedocs.io/en/stable/interactive/magics.html
数据整理
常规属性
In [2]:
# 加载数据并打印几行。进行这几项操作,来检查数据
# 类型,以及是否有缺失数据或错误数据的情况。
df_movies = pd.read_csv('./tmdb-movies.csv')
df_movies.head()
Out[2]:
本报告中需要用到的数据包含runtime,production_companies,vote_count,vote_average,budget_adj,revenue_adj。
production_companies 列筛选第一家主要的制作公司
In [3]:
df_movies.production_companies = df_movies.production_companies.str.split('|').str[0]
df_movies.head()
Out[3]:
5 rows × 21 columns
检查缺失值
In [4]:
df_movies.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10866 entries, 0 to 10865
Data columns (total 21 columns):
id 10866 non-null int64
imdb_id 10856 non-null object
popularity 10866 non-null float64
budget 10866 non-null int64
revenue 10866 non-null int64
original_title 10866 non-null object
cast 10790 non-null object
homepage 2936 non-null object
director 10822 non-null object
tagline 8042 non-null object
keywords 9373 non-null object
overview 10862 non-null object
runtime 10866 non-null int64
genres 10843 non-null object
production_companies 9836 non-null object
release_date 10866 non-null object
vote_count 10866 non-null int64
vote_average 10866 non-null float64
release_year 10866 non-null int64
budget_adj 10866 non-null float64
revenue_adj 10866 non-null float64
dtypes: float64(4), int64(6), object(11)
memory usage: 1.7+ MB
In [5]:
df_movies.describe()
Out[5]:
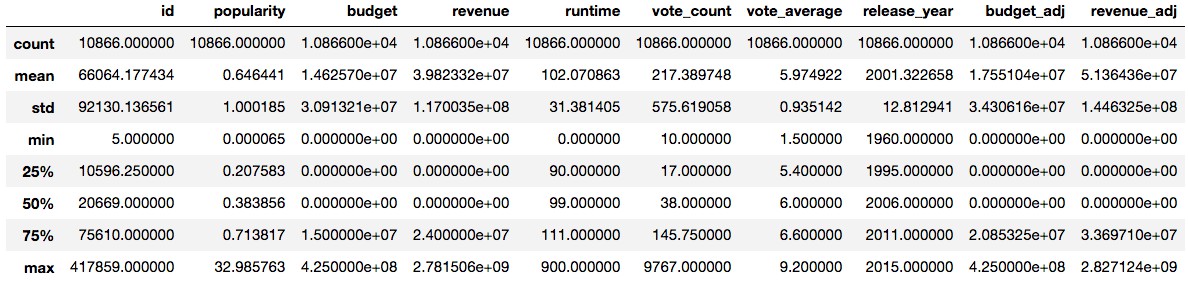
budget,runtime,budget_adj,revenue_adj 存在数据异常点,接下来对这些数据进行处理,去掉等于0的数据:
In [6]:
df_movies = df_movies[df_movies['budget'] > 0]
df_movies = df_movies[df_movies['runtime'] > 0]
df_movies = df_movies[df_movies['budget_adj'] > 0]
df_movies = df_movies[df_movies['revenue_adj'] > 0]
df_movies.describe()
Out[6]:
探索性数据分析
研究问题 1 受欢迎程度及评分的分布
向用户推荐电影时,电影的受欢迎程度和平均评分是主要的参考要素。接下来通过可视化观察受欢迎程度和平均评分的分布情况。
In [7]:
df_movies['popularity'].plot(kind = 'hist',bins = 200,title = 'The Distribution of Popularity(log)',logx = True,figsize = (8,5))
plt.ylabel('Count of Movies')
plt.xlabel('Popularity(log)');

In [8]:
df_movies['vote_average'].plot(kind = 'hist',bins = 30,title = 'The Distribution of Average Rating',figsize = (8,5))
plt.ylabel('Count of Movies')
plt.xlabel('Average Rating');

通过可视化可以发现,绝大部分的电影受欢迎程度在 10 以下,平均评分近似于正态分布,评分集中在5到7分之间。
研究问题 2 哪些公司的作品平均评分更高,更受欢迎?
可以把电影受欢迎和评分高的制作公司的电影推荐给用户。
按照制作公司对电影进行分类,再按照平均评分从高到低排名,列出前十家公司。
In [9]:
df_movies.groupby('production_companies')['vote_average'].mean().sort_values()[-10:].plot(kind = 'barh');
plt.title('Vote_average by production_companies',fontsize=18)
plt.xlabel('Vote_average')
plt.ylabel('Production_companies')
Out[9]:
Text(0,0.5,'Production_companies')

有些排名靠前的公司不是观众熟悉的知名公司,应该是这些公司的作品很少,评分又高。
接下来筛选作品数量大于等于 10 的制作公司,算出电影评分的平均值,列出排名前十的公司。
In [10]:
#筛选10部以上作品的制作公司
df_production_companies = pd.DataFrame(df_movies.production_companies.value_counts() >= 10)
#存为列表
list_production_companies = list(df_production_companies[df_production_companies['production_companies']].index)
#使用isin函数,筛选出原数据中在list_production_companies列表中的制作公司
df_movies[df_movies.production_companies.isin(list_production_companies)].groupby('production_companies')['vote_average'].mean().sort_values()[-10:].plot(kind = 'barh');
plt.title('Vote_average by production_companies',fontsize=18)
plt.xlabel('Vote_average')
plt.ylabel('Production_companies')
Out[10]:
Text(0,0.5,'Production_companies')

接下来筛选出作品数量大于等于 10 的制作公司,算出电影受欢迎程度的平均值,列出排名前十的公司。
In [11]:
# 使用isin函数,筛选出原数据中在list_production_companies列表中的制作公司
df_movies[df_movies.production_companies.isin(list_production_companies)].groupby('production_companies')['popularity'].mean().sort_values()[-10:].plot(kind = 'barh');
plt.title('Popularity by production_companies',fontsize=18)
plt.xlabel('Popularity')
plt.ylabel('Production_companies')
Out[11]:
Text(0,0.5,'Production_companies')

筛选出作品数量大于等于 10 的制作公司,从图中可以得知,受欢迎程度和平均得分排名靠前的 Walt Disney,Marvel,Pixar,Lucasfilm,DreamWorks等公司是观众熟悉的知名公司。
研究问题 3 票房高的电影有哪些特点?
计算电影票房与受欢迎度,平均评分,评价次数,电影预算的相关性。使用考虑了通货膨胀的数据。
In [16]:
#矩阵
df_movies[['runtime','popularity','vote_average','vote_count','budget_adj','revenue_adj']].corr()
Out[16]:
| runtime | popularity | vote_average | vote_count | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|
| runtime | 1.000000 | 0.215157 | 0.351909 | 0.273842 | 0.334011 | 0.280604 |
| popularity | 0.215157 | 1.000000 | 0.317924 | 0.780106 | 0.399375 | 0.546985 |
| vote_average | 0.351909 | 0.317924 | 1.000000 | 0.387271 | 0.036913 | 0.266996 |
| vote_count | 0.273842 | 0.780106 | 0.387271 | 1.000000 | 0.497988 | 0.654713 |
| budget_adj | 0.334011 | 0.399375 | 0.036913 | 0.497988 | 1.000000 | 0.570466 |
| revenue_adj | 0.280604 | 0.546985 | 0.266996 | 0.654713 | 0.570466 | 1.000000 |
由此可以看出,电影票房与受欢迎度(0.55),评价次数(0.65),电影预算(0.57)强相关,与平均评分和上映时间弱相关。
接下来可视化票房收入分别与受欢迎度、评价次数、电影预算相关性的散点图和线性回归线。
In [15]:
revenue_corr = df_movies[['popularity','vote_count','budget_adj','revenue_adj']]
fig = plt.figure(figsize=(18,6))
ax1 = plt.subplot(1,3,1)
ax1 = sns.regplot(x='popularity', y='revenue_adj', data=revenue_corr, x_jitter=.1)
ax1.text(0,2.5e9,'r=0.73',fontsize=18)
plt.title('revenue_adj by popularity',fontsize=18)
plt.xlabel('popularity',fontsize=15)
plt.ylabel('revenue_adj',fontsize=15)
ax2 = plt.subplot(1,3,2)
ax2 = sns.regplot(x='vote_count', y='revenue_adj', data=revenue_corr, x_jitter=.1,color='r',marker='1')
ax2.text(0,3.6e9,'r=0.64',fontsize=18)
plt.title('revenue_adj by vote_count',fontsize=18)
plt.xlabel('vote_count',fontsize=15)
plt.ylabel('revenue_adj',fontsize=15)
ax3 = plt.subplot(1,3,3)
ax3 = sns.regplot(x='budget_adj', y='revenue_adj', data=revenue_corr, x_jitter=.1,color='g',marker='v')
ax3.text(0,2.5e9,'r=0.73',fontsize=18)
plt.title('revenue_adj by budget',fontsize=18)
plt.xlabel('budget_adj',fontsize=15)
plt.ylabel('revenue_adj',fontsize=15)
Out[15]:
Text(0,0.5,'revenue_adj')
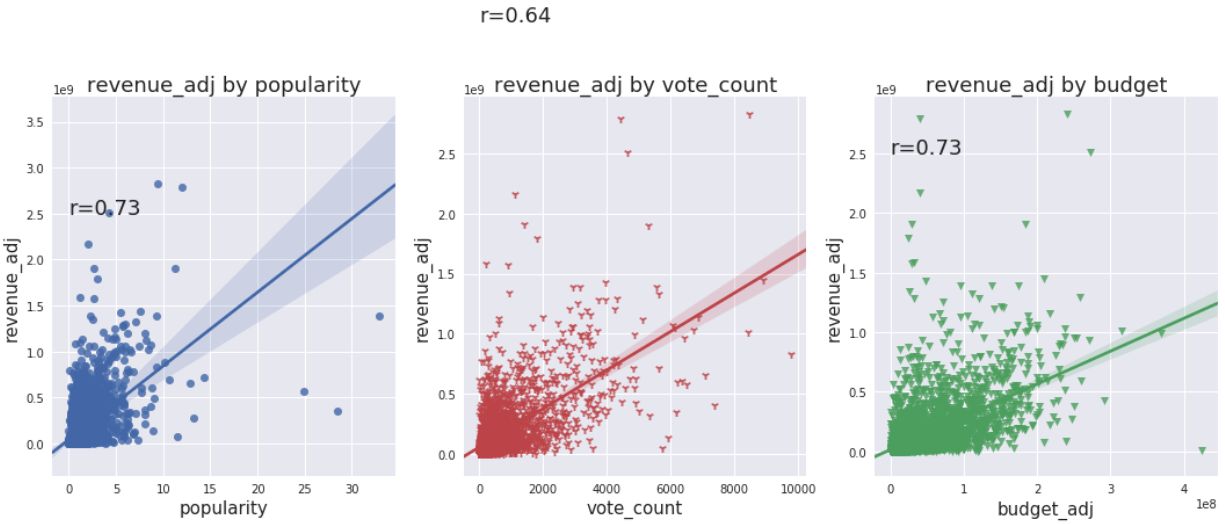
从图中可以看出,除去一些极值,电影票房与受欢迎度,评价次数,电影预算正相关。
结论
- 绝大部分的电影受欢迎程度在 10 以下,平均评分近似于正态分布,评分集中在5到7分之间。
- 筛选出作品数量大于等于 10 的制作公司后,Walt Disney,Marvel,Pixar,DreamWorks 等观众熟悉的知名公司的作品,平均评分更高,更受欢迎。
- 考虑通货膨胀的因素,除去一些极值,电影票房与受欢迎度,评价次数,电影预算正相关。预算是在电影上映前的可控因素,受欢迎度和投票数是电影上映后才有的统计数据,并不能确定是受欢迎和投票数高导致票房高,还是票房高导致受欢迎和投票数高。想要提高盈利,可以尝试增加预算,加大宣传,增加电影的受欢迎度和流行度,吸引观众去打分。
参考网页
-
pandas.DataFrame.corr
链接: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.corr.html
-
matplotlib.markers