import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
In [2]:
urllst = []
ui = 'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-'
for i in range(1,6):
urllst.append(ui +str(i))
urllst
Out[2]:
['https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-1',
'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-2',
'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-3',
'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-4',
'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-5']
爬取第一页景点信息
In [3]:
u1 = urllst[0]
r = requests.get(u1)
soup = BeautifulSoup(r.text,'lxml')
ul = soup.find('ul',class_='list_item clrfix')
li = ul.find_all('li')
datai = []
n=0
for i in li:
n += 1
dic = {}
dic['lat'] = i['data-lat']
dic['lng'] = i['data-lng']
dic['景点名称'] = i.find('span',class_="cn_tit").text
dic['攻略提到数量'] = i.find('div',class_="strategy_sum").text
dic['点评数量'] = i.find('div',class_="comment_sum").text
dic['景点排名'] = i.find('span',class_="ranking_sum").text
dic['星级'] = i.find('span',class_="total_star").find('span')['style'].split(':')[1]
datai.append(dic)
datai[:3]
# 显示前两条数据
Out[3]:
[{'lat': '31.146751',
'lng': '121.669396',
'景点名称': '上海迪士尼度假区SHDR:Shanghai Disney Resort',
'攻略提到数量': '157',
'点评数量': '19540',
'景点排名': '上海迪士尼度假区景点排名第1',
'星级': '96%'},
{'lat': '30.92078',
'lng': '121.913726',
'景点名称': '上海海昌海洋公园Shang Hai Haichang Ocean Park',
'攻略提到数量': '0',
'点评数量': '654',
'景点排名': '',
'星级': '86%'},
{'lat': '31.243453',
'lng': '121.497204',
'景点名称': '外滩The Bund',
'攻略提到数量': '1080',
'点评数量': '28139',
'景点排名': '上海景点排名第2',
'星级': '94%'}]
创建函数,获取网址url,采集上海景点的前5页
In [4]:
def get_urls(ui,n):
# ui:基础页面
# n:获取页码数
urllsti = []
for i in range(n):
urllsti.append(ui + str(i+1))
return urllsti
sh_u = 'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-'
urls = get_urls(sh_u,5)
print(urls)
# 创建函数,获取数据
def get_data(u):
# u:输入网址
ri = requests.get(u) # requests访问网站
soupi = BeautifulSoup(ri.text,'lxml') # bs解析页面
infori = soupi.find('ul',class_='list_item clrfix').find_all('li') # 获取列表内容
datai = []
n=0
for i in infori:
n += 1
# 分别获取字段内容
dic = {}
dic['lat'] = i['data-lat']
dic['lng'] = i['data-lng']
dic['景点名称'] = i.find('span',class_="cn_tit").text
dic['攻略提到数量'] = i.find('div',class_="strategy_sum").text
dic['点评数量'] = i.find('div',class_="comment_sum").text
dic['景点排名'] = i.find('span',class_="ranking_sum").text
dic['星级'] = i.find('span',class_="total_star").find('span')['style'].split(':')[1]
datai.append(dic)
return datai
get_data(urls[0])[:3]
['https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-1', 'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-2', 'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-3', 'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-4', 'https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-5']
Out[4]:
[{'lat': '31.146751',
'lng': '121.669396',
'景点名称': '上海迪士尼度假区SHDR:Shanghai Disney Resort',
'攻略提到数量': '157',
'点评数量': '19540',
'景点排名': '上海迪士尼度假区景点排名第1',
'星级': '96%'},
{'lat': '30.92078',
'lng': '121.913726',
'景点名称': '上海海昌海洋公园Shang Hai Haichang Ocean Park',
'攻略提到数量': '0',
'点评数量': '654',
'景点排名': '',
'星级': '86%'},
{'lat': '31.243453',
'lng': '121.497204',
'景点名称': '外滩The Bund',
'攻略提到数量': '1080',
'点评数量': '28139',
'景点排名': '上海景点排名第2',
'星级': '94%'}]
In [5]:
# 调用函数获取所有数据
sh_data = []
for i in urls:
sh_data.extend(get_data(i))
print('成功采集%i条数据'%len(sh_data))
#将数据放到DataFrame中
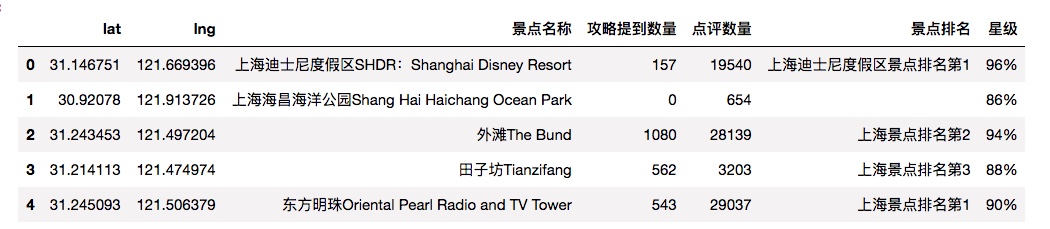
df = pd.DataFrame(sh_data)
df.head()
成功采集10条数据
成功采集20条数据
成功采集30条数据
成功采集40条数据
成功采集50条数据
Out[5]:
In [6]:
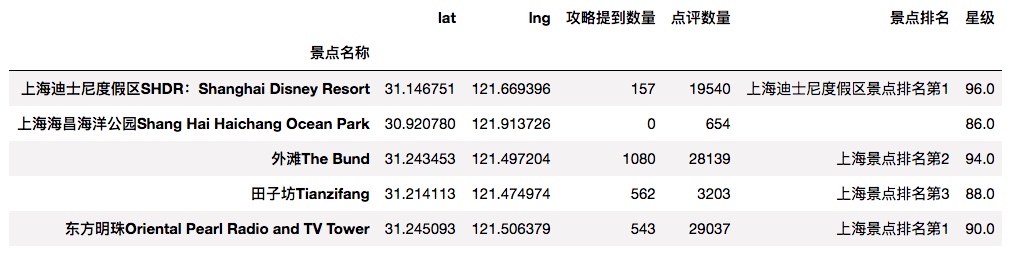
# 字段类型处理
df.index = df['景点名称']
del df['景点名称']
df['lng'] = df['lng'].astype(np.float)
df['lat'] = df['lat'].astype(np.float)
df['点评数量'] = df['点评数量'].astype(np.int)
df['攻略提到数量'] = df['攻略提到数量'].astype(np.int)
df['星级'] = df['星级'].str.replace('%','').astype(np.float)
df.head()
Out[6]:
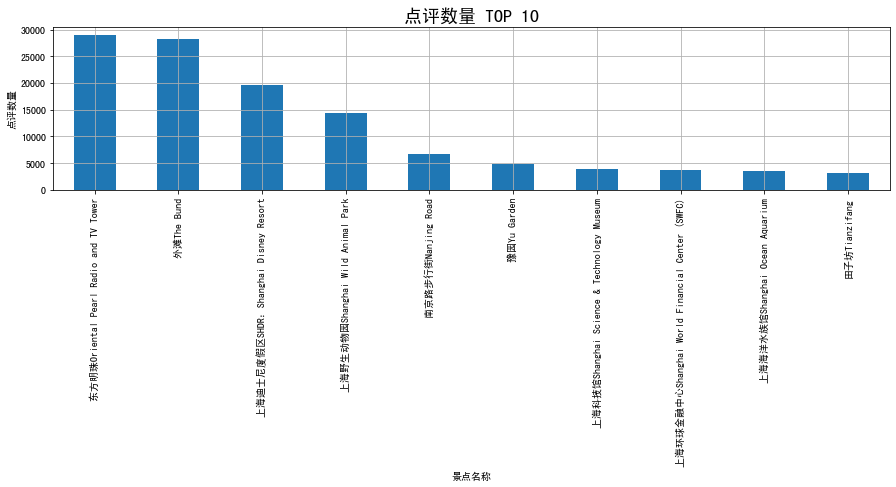
点评数量 TOP 10
In [7]:
dianping_top10 = df.sort_values(by = '点评数量',ascending=False).iloc[:10]
dianping_top10['点评数量'].plot(kind='bar',figsize=(15,3),rot=90,grid=True)
plt.title('点评数量 TOP 10', fontsize=18)
plt.xlabel('景点名称')
plt.ylabel('点评数量')
Out[7]:
Text(0, 0.5, '点评数量')
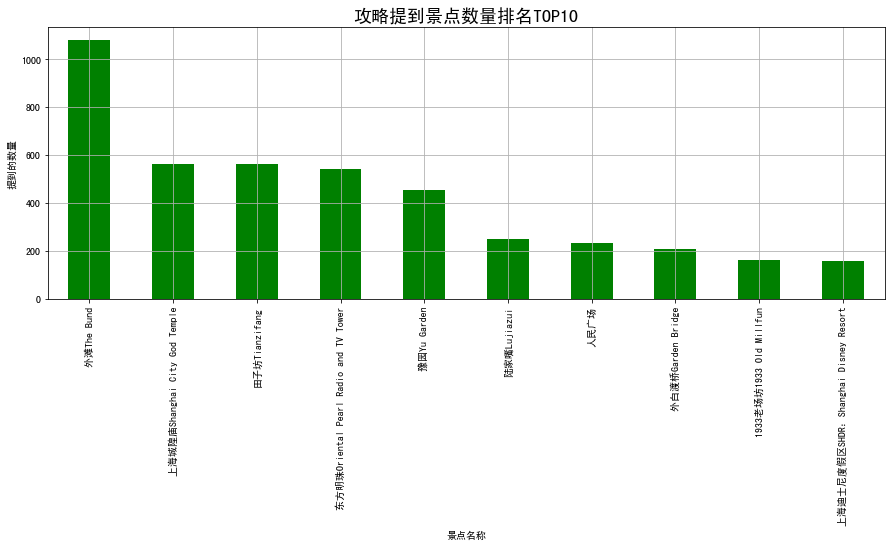
攻略提到景点数量排名TOP10
In [8]:
gonglue_top10 = df.sort_values(by = '攻略提到数量', ascending=False).iloc[:10]
gonglue_top10['攻略提到数量'].plot(kind='bar',figsize = (15,5),rot=90,grid=True,color='g')
plt.title('攻略提到景点数量排名TOP10', fontsize=18)
plt.xlabel('景点名称')
plt.ylabel('提到的数量')
Out[8]:
Text(0, 0.5, '提到的数量')
满意度指标
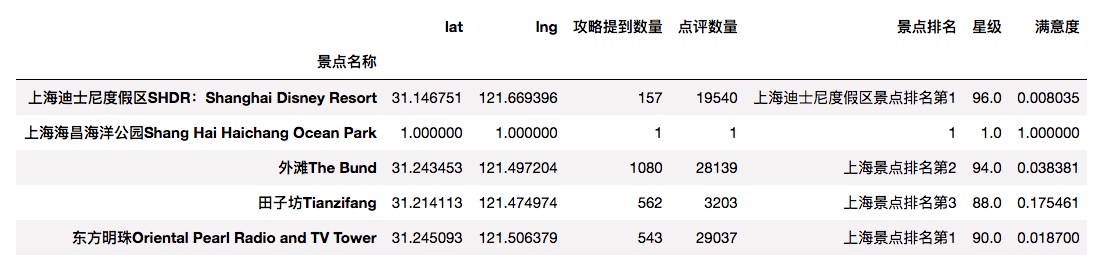
In [9]:
df[df['攻略提到数量']==0] = 1 #如果一次都没有提到按1计算
df['满意度']=df['攻略提到数量']/df['点评数量']
df['满意度'].fillna(value = 0,inplace = True)
df.head()
Out[9]:
标准化
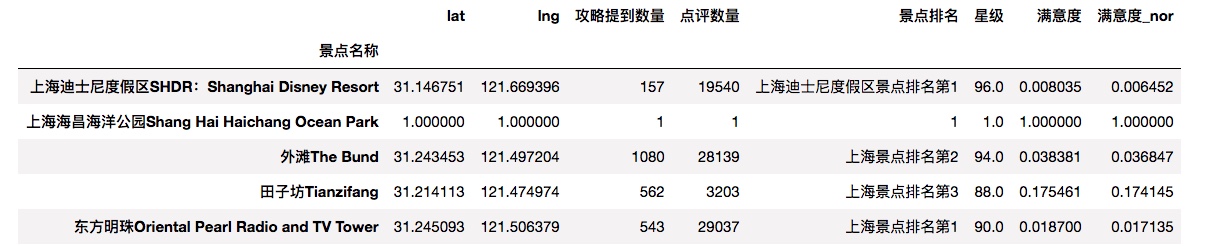
In [10]:
df['满意度_nor'] = (df['满意度'] - df['满意度'].min())/(df['满意度'].max()-df['满意度'].min())
df.head()
Out[10]:
In [11]:
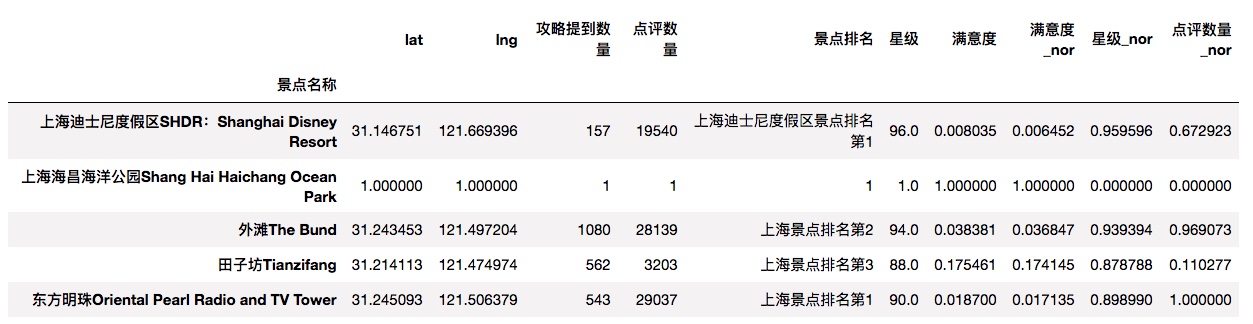
#构建函数,实现字段标准化
def nordata(dfi,*cols):
for col in cols:
dfi[col + '_nor'] = (dfi[col] - dfi[col].min())/(dfi[col].max() - dfi[col].min())
nordata(df,'满意度','星级','点评数量')
df.head()
Out[11]:
用 Excel 2016 制作三维地图
In [12]:
#导出数据
df.to_excel('/Users/alex/Documents/quna.xlsx')
#用 Excel 2016 插入三维地图
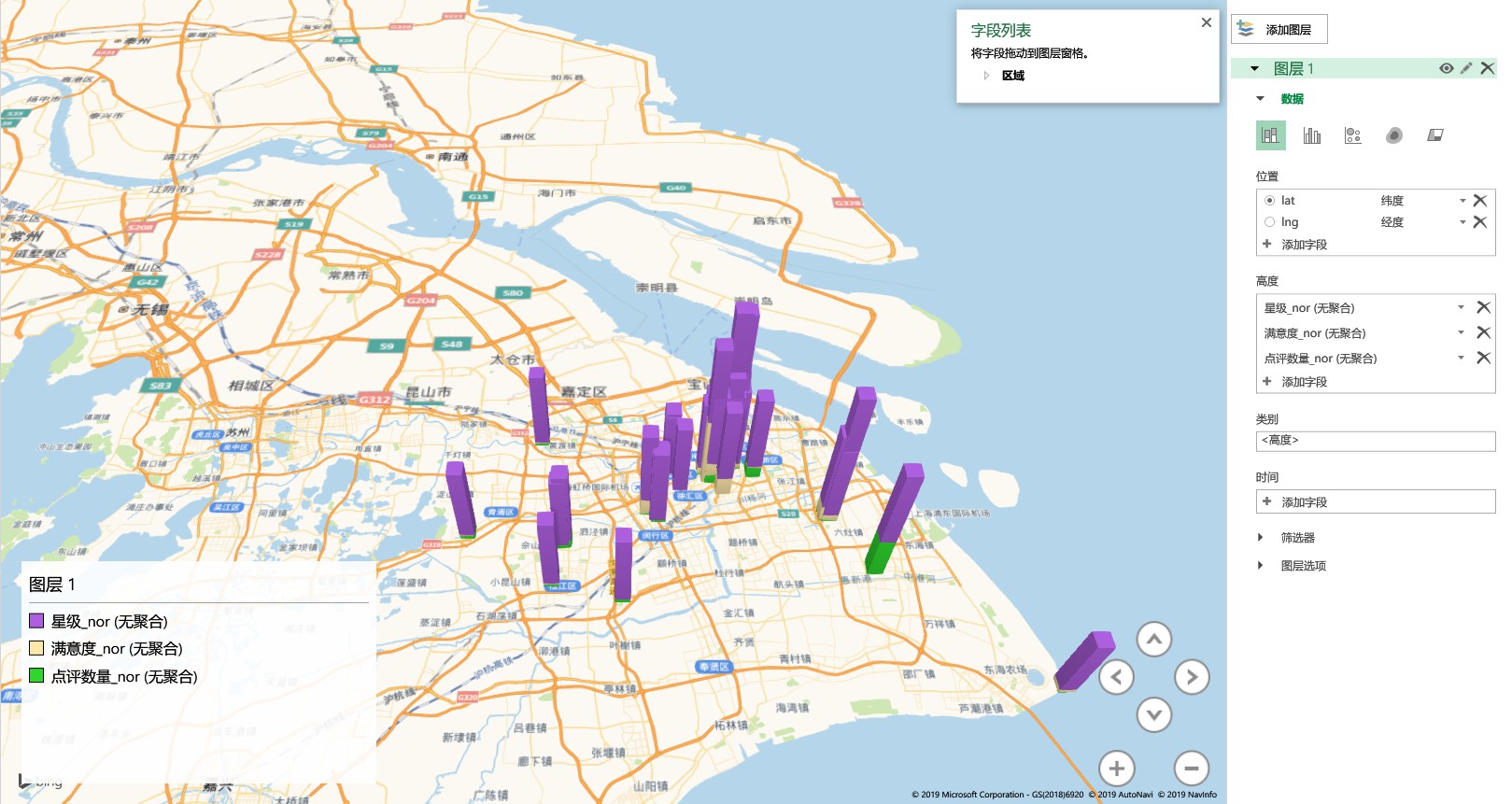
?