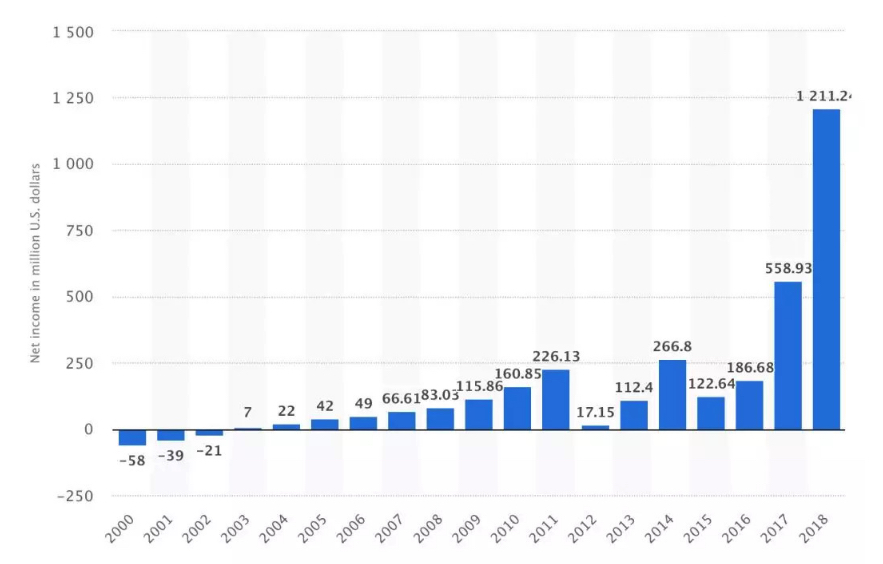
Netflix 网飞是一家以数据为导向的流媒体公司。
曾经热播的美剧《纸牌屋》帮助 Netflix 订户数超越传统的 HBO 电视网。2019年 Netflix的《爱、死亡、机器人》和《猎魔人》全网热播。

过去几年利润迅速增长,彰显了数据分析的价值,对用户偏好的洞察力,使他们能够做出明智的决策,提供最大的投资回报率。
本文将使用一些推荐算法构建个性化推荐系统。
数据处理
导入语句
import numpy as np
import pandas as pd
import math
import re
from scipy.sparse import csr_matrix
import matplotlib.pyplot as plt
import seaborn as sns
from surprise import Reader, Dataset, SVD
from surprise.model_selection import cross_validate
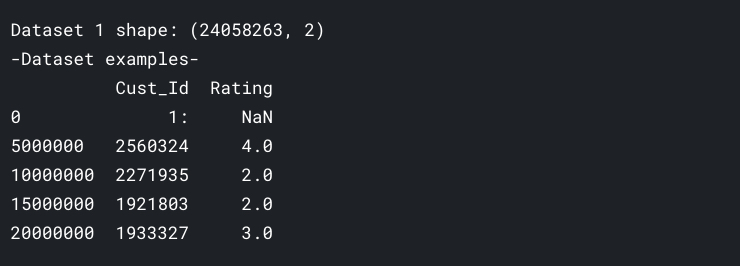
加载第一个数据文件,感受一下数据集有多大。
df1 = pd.read_csv('../input/netflix-prize-data/combined_data_1.txt', header = None, names = ['Cust_Id', 'Rating'], usecols = [0,1])
df1['Rating'] = df1['Rating'].astype(float)
print('Dataset 1 shape: {}'.format(df1.shape))
print('-Dataset examples-')
print(df1.iloc[::5000000, :])
接下来我们合并数据集
df = df1
#df = df1.append(df2)
#df = df.append(df3)
#df = df.append(df4)
df.index = np.arange(0,len(df))
print('Full dataset shape: {}'.format(df.shape))
print('-Dataset examples-')
print(df.iloc[::5000000, :])
查看数据
p = df.groupby('Rating')['Rating'].agg(['count'])
movie_count = df.isnull().sum()[1]
cust_count = df['Cust_Id'].nunique() - movie_count
rating_count = df['Cust_Id'].count() - movie_count
ax = p.plot(kind = 'barh', legend = False, figsize = (15,10))
plt.title('Total pool: {:,} Movies, {:,} customers, {:,} ratings given'.format(movie_count, cust_count, rating_count), fontsize=20)
plt.axis('off')
for i in range(1,6):
ax.text(p.iloc[i-1][0]/4, i-1, 'Rating {}: {:.0f}%'.format(i, p.iloc[i-1][0]*100 / p.sum()[0]), color = 'white', weight = 'bold')
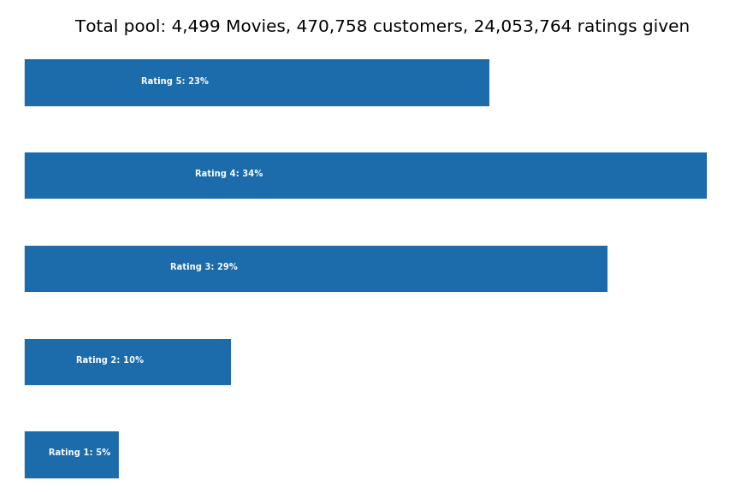
我们可以看到,3分以上的积极评分占多数。 这可能是因为不满意的观众倾向于直接离开,而不是去打分。
数据清洗
df_nan = pd.DataFrame(pd.isnull(df.Rating))
df_nan = df_nan[df_nan['Rating'] == True]
df_nan = df_nan.reset_index()
movie_np = []
movie_id = 1
for i,j in zip(df_nan['index'][1:],df_nan['index'][:-1]):
# numpy approach
temp = np.full((1,i-j-1), movie_id)
movie_np = np.append(movie_np, temp)
movie_id += 1
# 最后的记录及其长度
last_record = np.full((1,len(df) - df_nan.iloc[-1, 0] - 1),movie_id)
movie_np = np.append(movie_np, last_record)
print('Movie numpy: {}'.format(movie_np))
print('Length: {}'.format(len(movie_np)))

# 删除这些 Movie ID 行
df = df[pd.notnull(df['Rating'])]
df['Movie_Id'] = movie_np.astype(int)
df['Cust_Id'] = df['Cust_Id'].astype(int)
print('-Dataset examples-')
print(df.iloc[::5000000, :])
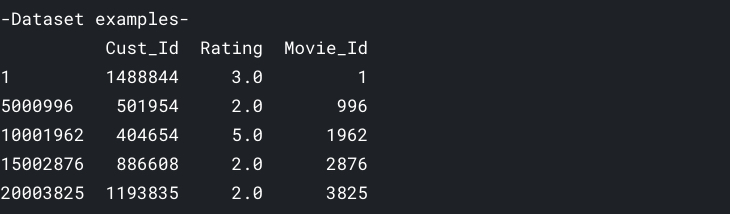
删除评论过少的电影和评论过少的用户数据。
f = ['count','mean']
df_movie_summary = df.groupby('Movie_Id')['Rating'].agg(f)
df_movie_summary.index = df_movie_summary.index.map(int)
movie_benchmark = round(df_movie_summary['count'].quantile(0.7),0)
drop_movie_list = df_movie_summary[df_movie_summary['count'] < movie_benchmark].index
print('Movie minimum times of review: {}'.format(movie_benchmark))
df_cust_summary = df.groupby('Cust_Id')['Rating'].agg(f)
df_cust_summary.index = df_cust_summary.index.map(int)
cust_benchmark = round(df_cust_summary['count'].quantile(0.7),0)
drop_cust_list = df_cust_summary[df_cust_summary['count'] < cust_benchmark].index
print('Customer minimum times of review: {}'.format(cust_benchmark))

print('Original Shape: {}'.format(df.shape))
df = df[~df['Movie_Id'].isin(drop_movie_list)]
df = df[~df['Cust_Id'].isin(drop_cust_list)]
print('After Trim Shape: {}'.format(df.shape))
print('-Data Examples-')
print(df.iloc[::5000000, :])
我们把数据转换成一个巨大的矩阵,推荐系统需要它。
df_p = pd.pivot_table(df,values='Rating',index='Cust_Id',columns='Movie_Id')
print(df_p.shape)

数据映射
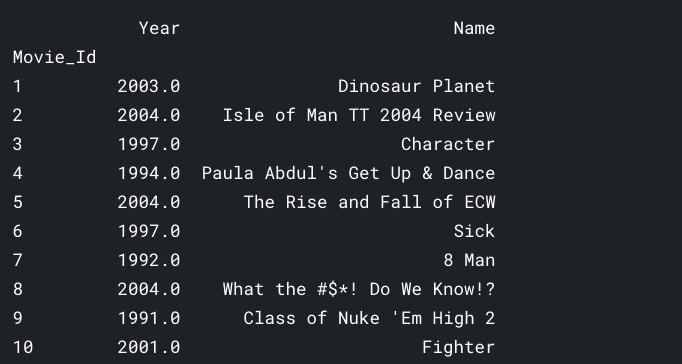
df_title = pd.read_csv('../input/netflix-prize-data/movie_titles.csv', encoding = "ISO-8859-1", header = None, names = ['Movie_Id', 'Year', 'Name'])
df_title.set_index('Movie_Id', inplace = True)
print (df_title.head(10))
推荐模型
协同过滤
我们将使用协同过滤向用户提供建议。
协同过滤基于这样的想法:找出与我喜好相似的用户,用来预测我会喜欢那些用户曾经使用过,但我还没有用过的产品或服务。
这里我将使用 Surprise 库,它使用了非常强大的算法,并给出了很好的推荐。
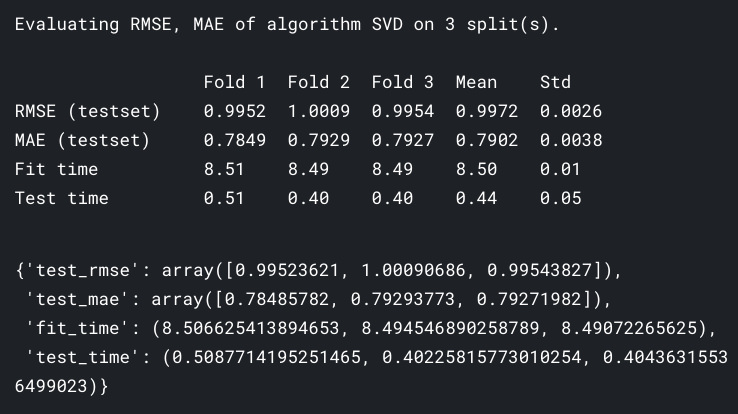
只用前 10 万行以实现更快的处理速度。
reader = Reader()
data = Dataset.load_from_df(df[['Cust_Id', 'Movie_Id', 'Rating']][:100000], reader)
# 使用著名的SVD算法
algo = SVD()
# 运行5次交叉验证
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3, verbose=True)
以下是用户 783514 过去喜欢的内容
df_785314 = df[(df['Cust_Id'] == 785314) & (df['Rating'] == 5)]
df_785314 = df_785314.set_index('Movie_Id')
df_785314 = df_785314.join(df_title)['Name']
print(df_785314)

让我们来预测用户 785314 还会喜欢看哪些电影
user_785314 = df_title.copy()
user_785314 = user_785314.reset_index()
user_785314 = user_785314[~user_785314['Movie_Id'].isin(drop_movie_list)]
# 获得完整的数据集
data = Dataset.load_from_df(df[['Cust_Id', 'Movie_Id', 'Rating']], reader)
trainset = data.build_full_trainset()
user_785314['Estimate_Score'] = user_785314['Movie_Id'].apply(lambda x: algo.predict(785314, x).est)
user_785314 = user_785314.drop('Movie_Id', axis = 1)
user_785314 = user_785314.sort_values('Estimate_Score', ascending=False)
print(user_785314.head(10))
皮尔逊积矩相关系数
我们使用皮尔逊积矩相关系数来衡量所有电影评论分数之间的线性相关性,然后提供相关性最高的前十部电影
def recommend(movie_title, min_count):
print("For movie ({})".format(movie_title))
print("- Top 10 movies recommended based on Pearsons'R correlation - ")
i = int(df_title.index[df_title['Name'] == movie_title][0])
target = df_p[i]
similar_to_target = df_p.corrwith(target)
corr_target = pd.DataFrame(similar_to_target, columns = ['PearsonR'])
corr_target.dropna(inplace = True)
corr_target = corr_target.sort_values('PearsonR', ascending = False)
corr_target.index = corr_target.index.map(int)
corr_target = corr_target.join(df_title).join(df_movie_summary)[['PearsonR', 'Name', 'count', 'mean']]
print(corr_target[corr_target['count']>min_count][:10].to_string(index=False))
如果你喜欢 What the #$*! Do We Know!?,以下是推荐给你的电影
recommend("What the #$*! Do We Know!?", 0)

如果你喜欢 X2: X-Men United,以下是推荐给你的电影
recommend("X2: X-Men United", 0)

总结
个性化推荐系统应用广泛、非常有效,为了推广纸牌屋,Netflix 甚至制作了十多种不同版本的预告片。如果用户观看了许多以女性为中心的影视剧,则会看到有关女性角色的预告片。如果用户观看了大卫·芬奇(David Finch)导演的许多作品,会看到聚焦在大卫·芬奇身上的预告片。
协同过滤系统也存在不足,新用户需要标记一些喜欢的影片,系统才能给出推荐,因此,新用户注册时,系统会邀请用户先选出一些自己喜欢的影片。
随着看过的影片越来越多,影片推荐系统需要进一步优化,最近播放的影片比以前播放的影片更重要。